
Contextual Music Recommendation
Duration: 2018 – 2022
Affiliation: Télécom Paris & Deezer Research, Paris
Supervisors: Dr. Gaël Richard, Dr. Geoffroy Peeters (Télécom Paris), Dr. Elena V. Epure (Deezer)
The Problem
We listen to different music when we are working out than when we are studying. We reach for different tracks when we are with friends than when we are alone. This is intuitive to anyone who uses a music streaming service — yet most recommendation systems still treat music listening as a single, context-free preference.
The goal of this project was to understand how the listening context — the combination of a user’s activity, mood, social setting, location, and device — shapes what music they want to hear, and to build intelligent systems that can predict this automatically at scale.
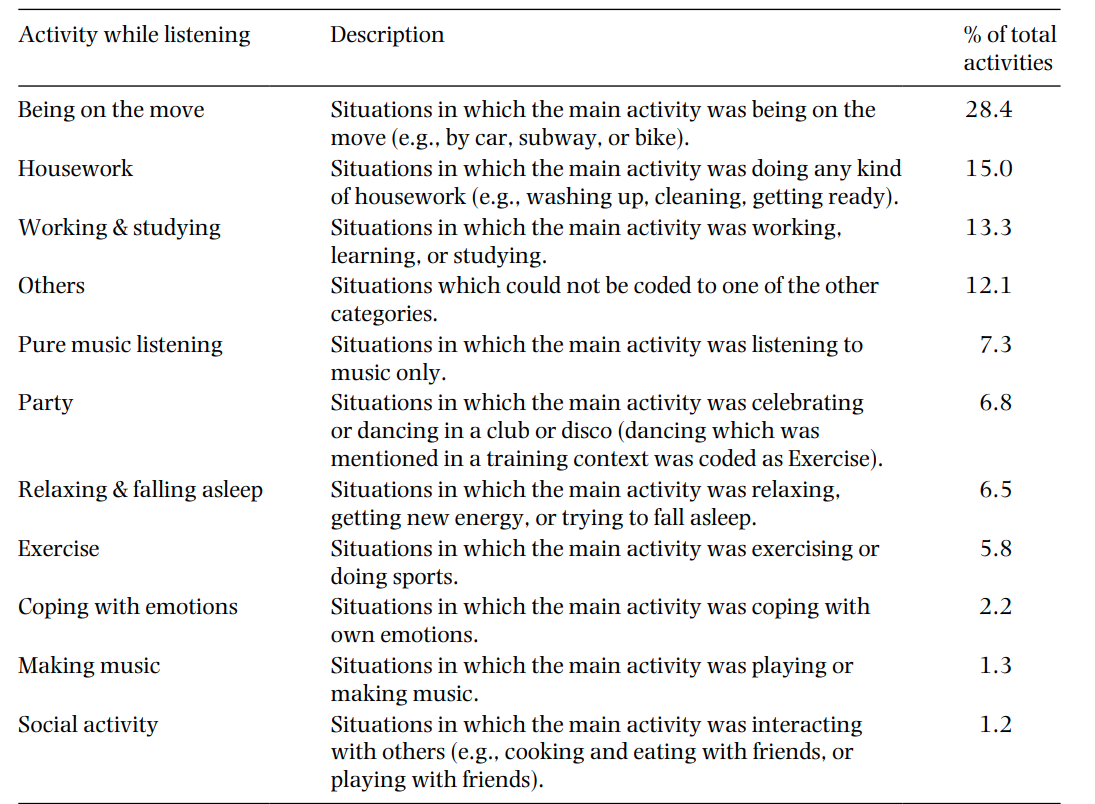
What is Context?
Context in music is multidisciplinary. It draws from psychology (how do situations influence listening preference?), information retrieval (how do we represent music content in a way that captures its contextual fit?), and machine learning (how do we build systems that learn this from data?).
Psychologists have long documented that people use music for specific functions — to manage mood, to energise activity, to signal identity, to accompany social settings. Those functions map to different musical features. A key challenge is mapping the abstract, language-based notion of “context” (e.g. “relaxing at home”, “working out”) onto the audio signal itself.

Representing Music for Context
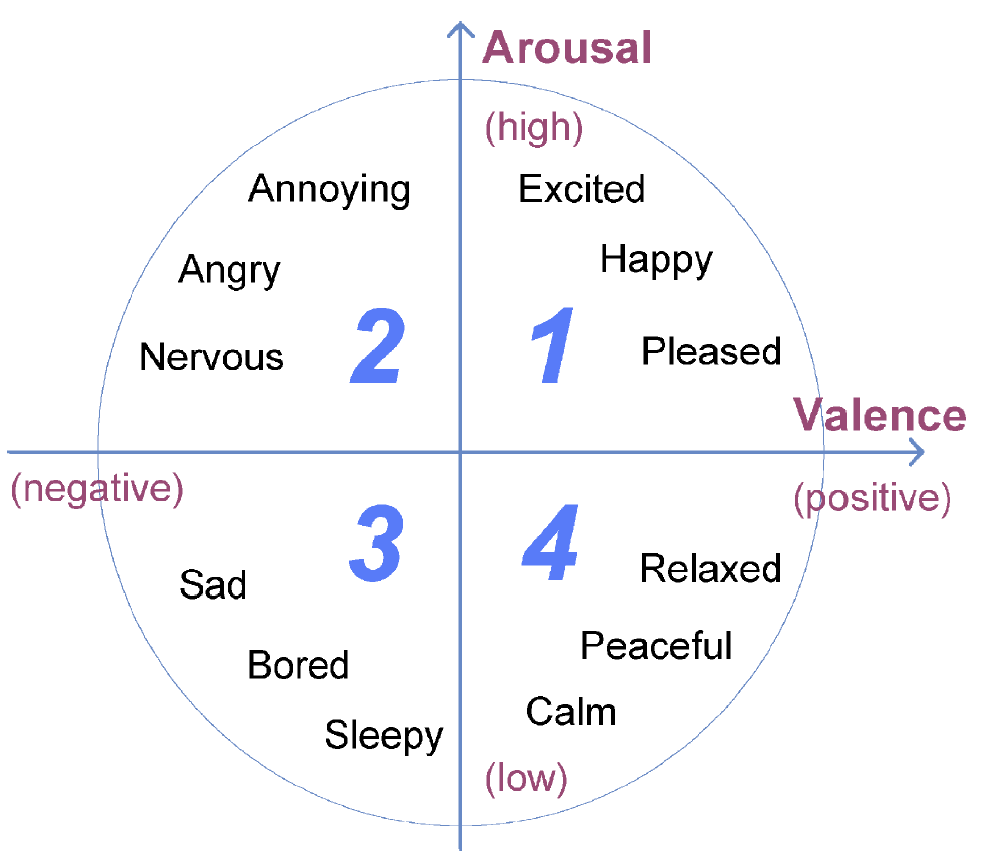
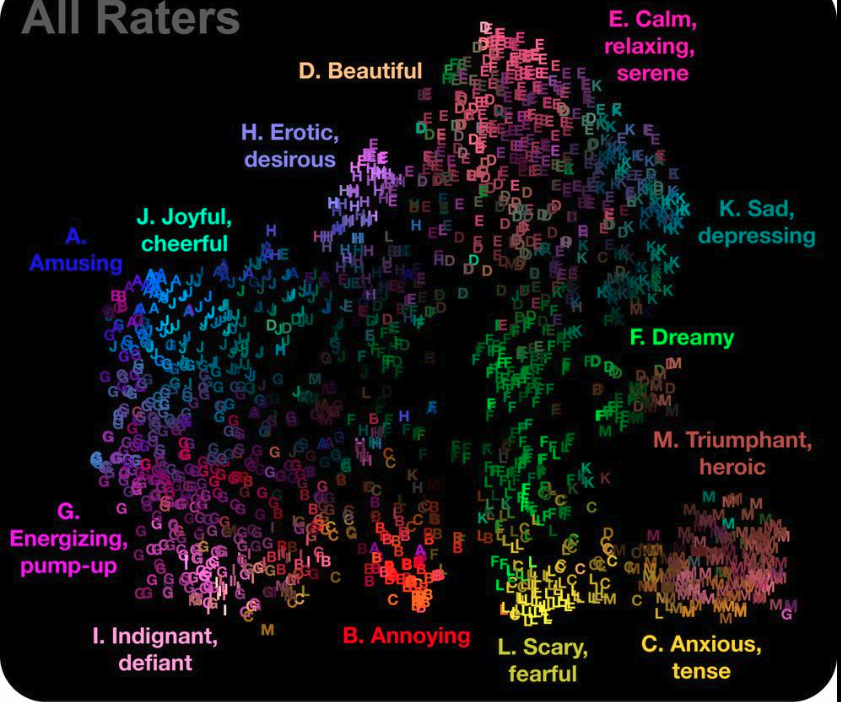
To connect audio content to contextual tags, we need good representations. One classic approach is the valence-arousal scale — a two-dimensional emotional map that places music according to how energetic and how positive it sounds. While useful, it is coarse. More powerful are learned embedding spaces, where music tracks are placed close together if they tend to be listened to in the same contexts.
The Research Arc
The project evolved through four published studies, each building on the last.
1. Building the dataset and baseline system — ICASSP 2020
We first needed data. We assembled a dataset of ~50,000 tracks labelled with 15 contextual tags (e.g. “workout”, “sleep”, “party”) and trained a model to predict these tags from audio alone. This established the first audio-based contextual auto-tagging baseline.
2. Learning with incomplete labels — ICMR 2020
In real-world datasets, not every track is labelled for every context. A track might be labelled “workout” but simply lack a “no sleep” label — it’s missing, not absent. We proposed a confidence-based weighted loss function that accounts for this ambiguity during training, improving performance significantly without requiring extra labelling effort.
3. Should the system know who is listening? — ISMIR 2020
Context is not just about the music — it is also about the listener. The same track might fit a morning commute for one person but a late-night study session for another. We built a user-aware auto-tagging system that combines audio content with a listener’s history to predict contextual tags per user, and proposed a new dataset annotated with per-user contextual labels.
4. Using device and sensor data as context signals — ISMIR 2022
A running user listening on earphones at 7am is a strong signal. We explored whether the device a user is listening on (phone, speaker, earphones) and the time of day can serve as proxy signals for context, eliminating the need for explicit mood or activity labels entirely. The results showed these passive signals carry surprisingly strong contextual information.
Publications
- Ibrahim, K. M., Royo-Letelier, J., Epure, E. V., Peeters, G., Richard, G. Audio-Based Auto-Tagging With Contextual Tags for Music. ICASSP 2020, Barcelona.
- Ibrahim, K. M., Epure, E. V., Peeters, G., Richard, G. Confidence-based Weighted Loss for Multi-label Classification with Missing Labels. ICMR 2020, Dublin.
- Ibrahim, K. M., Epure, E. V., Peeters, G., Richard, G. Should We Consider the Users in Contextual Music Auto-Tagging Models?. ISMIR 2020, Montreal.
- Ibrahim, K. M., Epure, E. V., Peeters, G., Richard, G. Exploiting Device and Audio Data to Tag Music with User-Aware Listening Contexts. ISMIR 2022, Bengaluru.