
Mood Monitoring with Speech Emotion Recognition
Duration: 2023 – 2024
Affiliation: Emobot, Paris
The Problem
Understanding how a person feels from the way they speak is a genuinely hard problem. The same sentence — “I’m fine” — can carry frustration, relief, sarcasm, or genuine calm depending on how it is delivered. Speech emotion recognition (SER) systems try to read these signals automatically, from the acoustic properties of a voice: pitch, energy, rhythm, and spectral texture.
The challenge is data. Collecting large, naturally labelled speech emotion datasets is expensive and slow. Actors can be recorded, but acted emotion sounds different from spontaneous emotion. And spontaneous emotion in the wild is difficult to annotate reliably. Most existing datasets are small, which limits how well supervised models can generalise.
The Approach: Learning from Synthetic Data
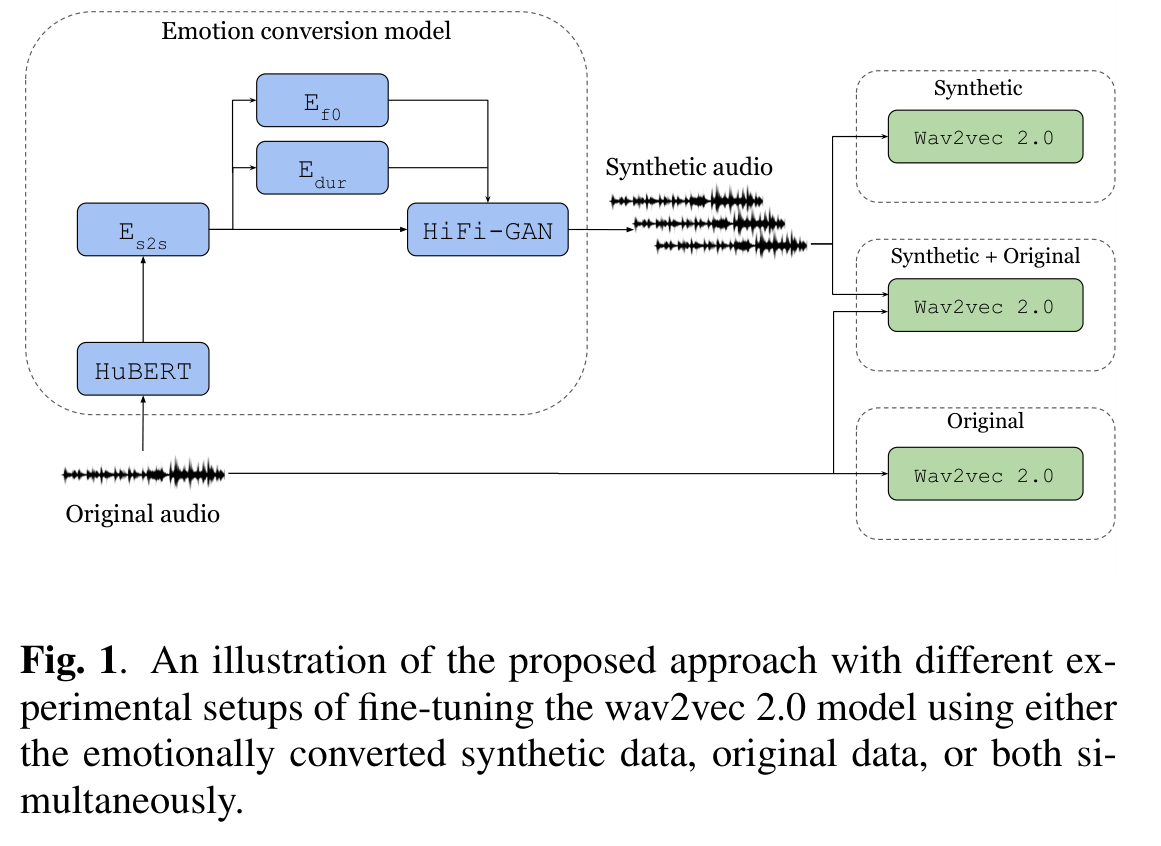
Our approach was to sidestep the data scarcity problem by generating it. Emotion conversion models — systems trained to re-synthesise a neutral speech recording in a target emotional style — can turn a small labelled set into a much larger one. A sentence recorded in a neutral tone can be converted to sound angry, or sad, or joyful, and used to augment training.
The key research question was: does a model trained on this synthetic augmented data actually perform better on real, spontaneous speech? And under what conditions does the augmentation help versus introduce noise?
We showed that with the right augmentation strategy, synthetic emotion data provides meaningful gains in recognition accuracy, and that the benefit scales with the quality of the emotion conversion model used.
Impact
The work fed directly into a real-time emotion monitoring application in a healthcare context, where the system analyses patient speech to support clinical assessment. Improving accuracy here is not just a benchmark exercise — it has real implications for how well the system can support practitioners.
Publication
- Ibrahim, K. M., Perzo, A., Leglaive, S. Towards Improving Speech Emotion Recognition Using Synthetic Data Augmentation from Emotion Conversion. ICASSP 2024, Seoul.